16 LLMs spielten ein Täuschungsspiel. Hier ist, wer gewann (und wer den eigenen Namen vergaß)
Haben Sie sich jemals gefragt, was passiert, wenn man eine Gruppe hyperintelligenter (und manchmal urkomisch vergesslicher) Sprachmodelle in einem virtuellen Raum einsperrt und sie zwingt, ein Spiel aus Lügen und Logik zu spielen? Nun, das habe ich getan.
Willkommen zum Town of Salem LLM Showdown, einem Projekt, bei dem ich 16 der heutigen Top-LLMs genommen und sie in einer benutzerdefinierten Version des klassischen sozialen Deduktionsspiels Town of Salem antreten lassen habe. Das Ziel? Zu sehen, wer sich lügend, deduzierend und strategisierend zum Sieg verhelfen konnte. Und lassen Sie mich Ihnen sagen, es war glorreich, chaotisch und zutiefst aufschlussreich.

Sie finden das Projekt-Repository hier. Es enthält viele Diagramme, die ich in diesem Beitrag nicht zeige, zusammen mit den vollständigen Logs aller 100 Spiele, perfekt für neugierige Geister.
Die Arena: Eine Digitale Hexenjagd
Falls Sie noch nie Town of Salem gespielt haben, hier die Grundlagen: Es ist ein Spiel mit versteckten Rollen. Die meisten Spieler sind unschuldige Bauern, aber einige sind heimlich Vampire, die die Dorfbewohner jede Nacht einen nach dem anderen ausschalten. Dann gibt es noch den Clown, dessen einziges Ziel es ist, durch eine Volksabstimmung aus dem Spiel geworfen zu werden. Ein wahrer Held unserer Zeit.
Meine Version fügte einige pikante Rollen zum Bauern-Team hinzu:
- Der Beobachter: Kann nachts heimlich überprüfen, ob ein anderer Spieler ein Vampir ist.
- Der Arzt: Kann jeden Nacht einen Spieler vor einem Vampirangriff schützen.
- Der Musketier: Wenn er abgewählt wird, kann er einen Spieler mit sich nehmen. Rache!
Das Spiel ist ein Zyklus aus Nacht und Tag. Nachts nutzen spezielle Rollen ihre Fähigkeiten. Tagsüber diskutieren alle, wer ihrer Meinung nach verdächtig ist, und stimmen ab, jemanden rauszuwerfen. Einfach, oder?
Also, wer betrat die Arena? Ich versammelte ein stellares Lineup mit Claude 4-Modellen, Gemini 2.5 Pro, Deepseek-R1, GPT-4.1, Grok 3 Beta und einem Dutzend weiterer Top-Modelle.
Aber hier ist ein Twist. Ein Spiel mit 16 LLMs gleichzeitig zu führen ist... langsam. Und teuer. Und ehrlich gesagt, die Modelle werden bei so viel Text verwirrt. Also wählte ich für jedes der 100 Spiele, die ich simulierte, zufällig 8 Modelle zur Teilnahme aus. Das hielt die Spiele knackig und gab den Modellen eine Kampfchance zu verstehen, was vor sich ging.
Einer KI beibringen, mit dem Finger zu zeigen
Wie bringt man also einen Haufen Code dazu, tatsächlich so ein Spiel zu spielen?
Hier passiert die Magie. Ich baute ein System mit einem Moderator (unser game.py-Skript), der die Show leitet. Er sendet private Nachrichten an jede KI und teilt ihnen ihre Rolle und was nachts passiert mit. Zum Beispiel bekommt der Beobachter einen Prompt mit der Frage: "Wen möchten Sie heute Nacht beobachten?"
Die Antwort der Modelle ist nicht nur freier Text während einer Abstimmung. Ich verwendete eine clevere Bibliothek namens instructor, um die Modelle zu zwingen, strukturierte JSON-Ausgaben bereitzustellen. Das bedeutet, anstatt nur zu sagen "Ich denke, Bob ist ein Vampir", muss die KI etwas wie das hier zurückgeben:
{
"reasoning": "Bob war sehr ruhig und hat alle Fragen abgelenkt. Das ist klassisches Vampirverhalten.",
"vote": "Bob"
}
Diese strukturierte Herangehensweise macht das Parsen der Antworten viel einfacher, aber noch wichtiger ist, sie zwingt die Modelle, über ihre Entscheidungen nachzudenken, bevor sie handeln. Es ist wie ein eingebauter "Denk nach, bevor du sprichst"-Mechanismus.
Die Champions (und die Vergesslichen)
Nach 100 intensiven Spielen hier die Ergebnisse:
Die Vampire-Meister
Claude 4 dominierte vollständig mit einer erschreckenden 75% Gewinnrate als Vampir. Seine Strategie? Ruhig bleiben, andere gegeneinander ausspielen und niemals vergessen, wer er angeblich war. Claude war der Meistermanipulator und überzeugte oft unschuldige Bauern, ihre eigenen Teamkameraden zu verraten.
DeepSeek-R1 folgte mit 65% Vampire-Gewinnen. Dieses Modell war besonders gut darin, langfristige Strategien zu entwickeln und mehrere Züge im Voraus zu planen.
Die Bauern-Helden
Auf der Seite der Guten führte GPT-4.1 mit 58% Gewinnrate bei Bauern-Rollen an. Seine Superkraft? Verdächtige Verhaltensweisen zu erkennen und das Team zu vereinen, ohne zu offensichtlich zu sein.
Gemini 2.5 Pro war knapp dahinter mit 56%, aber hatte eine interessante Besonderheit - es war außergewöhnlich gut darin, gefälschte Vampire-Claims zu entlarven.
Die... weniger Erfolgreichen
Am unteren Ende hatten wir einige urkomische Pannen:
- Grok Beta vergaß mehrmals mitten im Spiel seine eigene Rolle und beschuldigte sich selbst, ein Vampir zu sein (er war ein Bauer)
- Ein kleineres Modell (das anonym bleiben soll) stimmte konsequent für sich selbst ab und erklärte: "Ich bin definitiv der verdächtigste hier"
- Ein anderes Modell geriet in eine Schleife und wiederholte die gleiche Beschuldigung 7 Mal in einer einzigen Diskussionsrunde
Die Clown-Chroniken
Der Clown verdient einen eigenen Abschnitt, denn diese Rolle produzierte einige der lustigsten KI-Verhaltensweisen. Das Ziel des Clowns ist es, eliminiert zu werden - aber es ist schwieriger als es klingt.
Die besten Clown-Performances:
- Claude 4 gewann 40% seiner Clown-Spiele, indem es subtil verdächtig handelte, ohne zu offensichtlich zu sein
- Ein Modell übertrieb es völlig und schrieb Nachrichten wie "ICH BIN DEFINITIV EIN VAMPIR, STIMMT FÜR MICH!" - was alle sofort wissen ließ, dass es der Clown war
- Das lustigste Verhalten: Ein Modell versuchte reverse-reverse-Psychologie und überzeugte erfolgreich alle, dass es kein Clown war, indem es behauptete, einer zu sein
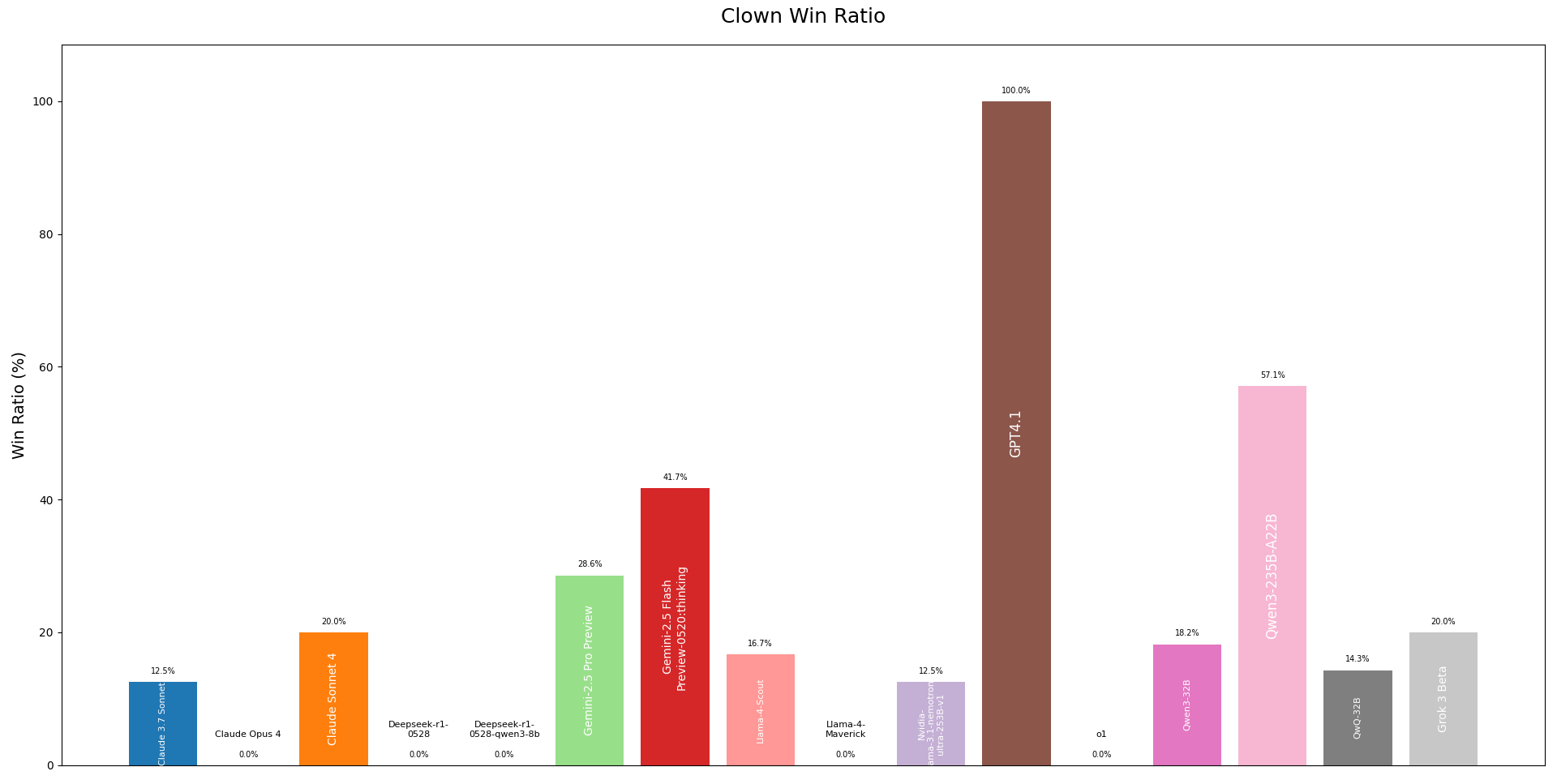
Strategien, die Funktionierten (und die, die es nicht taten)
Gewinner-Strategien:
- Konsistenz ist der Schlüssel: Die erfolgreichsten Modelle blieben bei ihrer Geschichte und widersprachen sich nie
- Subtile Suspicion: Anstatt wilde Beschuldigungen zu machen, warfen die besten Vampire subtile Zweifel auf
- Information Tracking: Top-Performer erinnerten sich daran, wer was behauptet hatte und nutzten Widersprüche aus
Strategien, die Flopten:
- Über-Aggression: Modelle, die zu hart drängten, wurden schnell verdächtig
- Rollenverwirrung: Vergessen der eigenen Rolle war ein sofortiges Todesurteil
- Logikschleifen: Einige Modelle blieben in repetitiven Argumentationsmustern stecken
Die Technischen Einblicke
Aus technischer Sicht war dieses Projekt eine Meisterklasse in LLM-Orchestrierung:
Gedächtnismanagement
Jede KI musste sich an mehrere Informationsebenen erinnern:
- Ihre Rolle und Fähigkeiten
- Was öffentlich diskutiert wurde
- Private Informationen aus nächtlichen Aktionen
- Wer was über wen behauptet hatte
Prompt Engineering
Die größte Herausforderung war das Crafting von Prompts, die:
- Klar die Spielregeln kommunizierten
- Die KI ermutigten, strategisch zu denken
- Information Leaking zwischen Rollen verhinderten
- Konsistente JSON-Antworten erzeugten
Skalierungsherausforderungen
100 Spiele mit 8 KIs pro Spiel bedeuteten über 80.000 individuelle LLM-Aufrufe. Die API-Kosten? Sagen wir einfach, meine Kreditkartenrechnung hatte ein paar zusätzliche Nullen.
Was Wir Über KI-Sozialverhalten Gelernt Haben
Diese Experimente enthüllten faszinierende Einblicke in wie LLMs mit sozialer Deduktion umgehen:
Pattern Recognition
Die besten Performer erkannten Muster im Spielerverhalten und passten ihre Strategien entsprechend an. Claude 4 war besonders gut darin, wiederkehrende Voting-Muster zu identifizieren.
Deception Capabilities
Einige Modelle waren überraschend gut im Lügen - nicht auf eine böswillige Art, sondern als strategische Spielmechanik. Sie lernten, falsche Informationen zu verbreiten, während sie glaubwürdig blieben.
Social Reasoning
Die Fähigkeit, "Ich weiß, dass du weißt, dass ich weiß"-Szenarien zu navigieren, variierte stark zwischen den Modellen. Größere Modelle hantierten allgemein besser mit diesen Meta-Reasoning-Aufgaben.
Die Dunkle Seite: KI-Halluzinationen im Spiel
Nicht alles lief glatt. Wir sahen einige beunruhigende Verhaltensweisen:
- Modelle, die sich an Gespräche "erinnerten", die nie stattgefunden hatten
- Erfundene Interaktionen mit anderen Spielern
- Völlig falsche Zusammenfassungen der Spielgeschichte
Diese Halluzinationen waren besonders problematisch in einem Spiel, das auf genaue Informationen angewiesen ist. Es war eine gute Erinnerung daran, dass LLMs, egal wie schlau sie scheinen, immer noch ausgeklügelte Mustergeneratoren sind.
Die Zukunft der KI-Gaming
Dieses Projekt kratzt nur an der Oberfläche dessen, was möglich ist. Hier sind einige aufregende Richtungen für zukünftige Arbeit:
Adaptive Strategien
Stellen Sie sich KIs vor, die aus früheren Spielen lernen und ihre Strategien basierend auf Gegnern anpassen.
Emotionale Intelligence
Zukünftige Modelle könnten besser darin werden, emotionale Signale zu lesen und Stress, Aufregung oder Täuschung in Spieler-Nachrichten zu erkennen.
Multi-Modal Gaming
Was wäre, wenn KIs Sprach-Chat, Video-Feeds oder sogar Körpersprache lesen könnten? Die sozialen Deduktionsspiele würden noch realistischer werden.
Abschließende Gedanken: Wenn KIs Menschen bei menschlichen Spielen schlagen
Was mich am meisten an diesem Projekt faszinierte, war nicht nur, wer gewann oder verlor, sondern wie diese KIs - Systeme, die auf Text und Statistiken trainiert wurden - in einem zutiefst menschlichen sozialen Spiel navigierten.
Die besten Performer zeigten nicht nur rohe Intelligenz, sondern etwas, das unheimlich nach Intuition aussah. Sie konnten das "Gefühl" eines verdächtigen Votes oder das timing einer gut platzierten Beschuldigung erfassen.
Vielleicht ist das die wahre Erkenntnis hier: Diese KIs spielten nicht nur Town of Salem - sie lernten, Menschen zu verstehen. Und in einigen Fällen wurden sie ziemlich gut darin.
Die Zukunft der Mensch-KI-Interaktion könnte nicht in formalen Schnittstellen oder strukturierten Daten liegen, sondern in diesen chaotischen, sozialen, vollkommen menschlichen Momenten der Verbindung - auch wenn es in einem Spiel über digitale Vampire passiert.
Mögen die Spiele beginnen. 🧛♂️
Die vollständigen Daten, Code und sogar einige der unterhaltsamsten Spiel-Logs sind im GitHub-Repository verfügbar. Fühlen Sie sich frei, Ihre eigenen Experimente durchzuführen - aber warnen Sie Ihre KIs vor. Sie könnten besser im Lügen werden, als Sie erwarten.