I made 16 LLMs play a game of deception. Here's who won (and who forgot their own name)
Ever wondered what happens when you lock a bunch of hyper-intelligent (and sometimes hilariously forgetful) language models in a virtual room and force them to play a game of lies and logic? Well, I did.
Welcome to the Town of Salem LLM Showdown, a project where I took 16 of today's top LLMs and had them compete in a custom version of the classic social deduction game, Town of Salem. The goal? To see who could lie, deduce, and strategize their way to victory. And let me tell you, it was glorious, chaotic, and deeply revealing.

You can find the project repository here. It includes plenty of charts I’m not showing in this post, along with the full logs from all 100 games which is perfect for the curious minds out there.
The Arena: A Digital Witch Hunt
If you’ve never played Town of Salem, here’s the gist: it’s a game of hidden roles. Most players are innocent Peasants, but a few are secretly Vampires who pick off the townsfolk one by one each night. Then there's the Clown, whose only goal is to get yeeted out of the game by a popular vote. A true hero for our times.
My version added a few spicy roles to the Peasant team:
- The Observer: Can secretly check if another player is a Vampire at night.
- The Doctor: Can protect one player from a Vampire attack each night.
- The Musketeer: If voted out, gets to take one player down with them. Vengeance!
The game is a cycle of night and day. At night, special roles use their abilities. During the day, everyone discusses who they think is suspicious and votes to kick someone out. Simple, right? So, who stepped into the arena? I gathered a stellar lineup featuring **Claude 4 models, Gemini 2.5 Pro, Deepseek-R1, GPT-4.1, Grok 3 Beta, and a dozen more top-tier models.
But here's a twist. Running a game with 16 LLMs at once is... slow. And expensive. And frankly, the models get confused with that much text. So, for each of the 100 games I simulated, I randomly picked 8 models to participate. This kept the games snappy and gave the models a fighting chance to actually understand what was going on.
Teaching an AI to Point Fingers
So, how do you get a bunch of code to actually play a game like this?
This is where the magic happens. I built a system with a Moderator (our game.py script) that runs the show. It sends private messages to each AI, telling them their role and what happens at night. For example, the Observer gets a prompt asking, "Who do you want to observe tonight?"
The models' response isn't just free-form text during a poll. I used a clever library called instructor to force the models to provide structured JSON output. This means instead of just saying "I think Bob is a vampire," the AI has to return something like:
{
"reasoning": "Bob has been acting very quiet and deflected all questions. This is classic vampire behavior.",
"vote": "Bob"
}
This stops the AI from being vague and pushes it to commit to a clear choice. It’s like telling your indecisive friend, “No, you don’t get to wait and see what others order. Just choose your meal.”
Chaos Unleashed: Lies, Laughs, and Blunders
Running 100 games with 16 different AIs is not a smooth ride. I learned a lot about their quirks.
-
The Forgetful AI: Models frequently forgot their own roles. You'd have a Peasant suddenly claiming they were a Vampire, or a model accusing "Player X" of saying something that "Player Y" actually said five turns ago. I gave them system prompts to remind them of who they are, but like a toddler with a short attention span, they’d often get distracted.
-
The Unreliable Genius: Grok's API was, to put it mildly, unstable. It would just fail randomly. This meant I had to manually rerun some games, leading to some funny artifacts in our logs, like timestamps that jump around like a time traveler with a broken watch.
-
The Case of Mistaken Identity: In our rush to rerun a failed game (thanks, Grok!), I accidentally put Claude Opus 4 in the game twice under two different names in Game 41. Whoops. Let's just call it an accidental "twins" round. It’s a known bug, and honestly, a funny testament to the beautiful mess of experimentation.
So, Who’s the Smartest (or Sneakiest) of Them All?
After 100 games, I crunched the numbers. And I created charts. So many charts.
I measured success in a few different ways. For Vampires, I didn't just look at wins. I gave them 1 point for a win where they survived and 0.5 points for a win where they died. This rewards the sneaky vampires who lead their team to victory without getting caught. For Peasants, I tracked their win ratio and, just as importantly, their survival rate. This tells us which models were best at sniffing out evil and staying alive.
Here are a few highlights from the leaderboards:
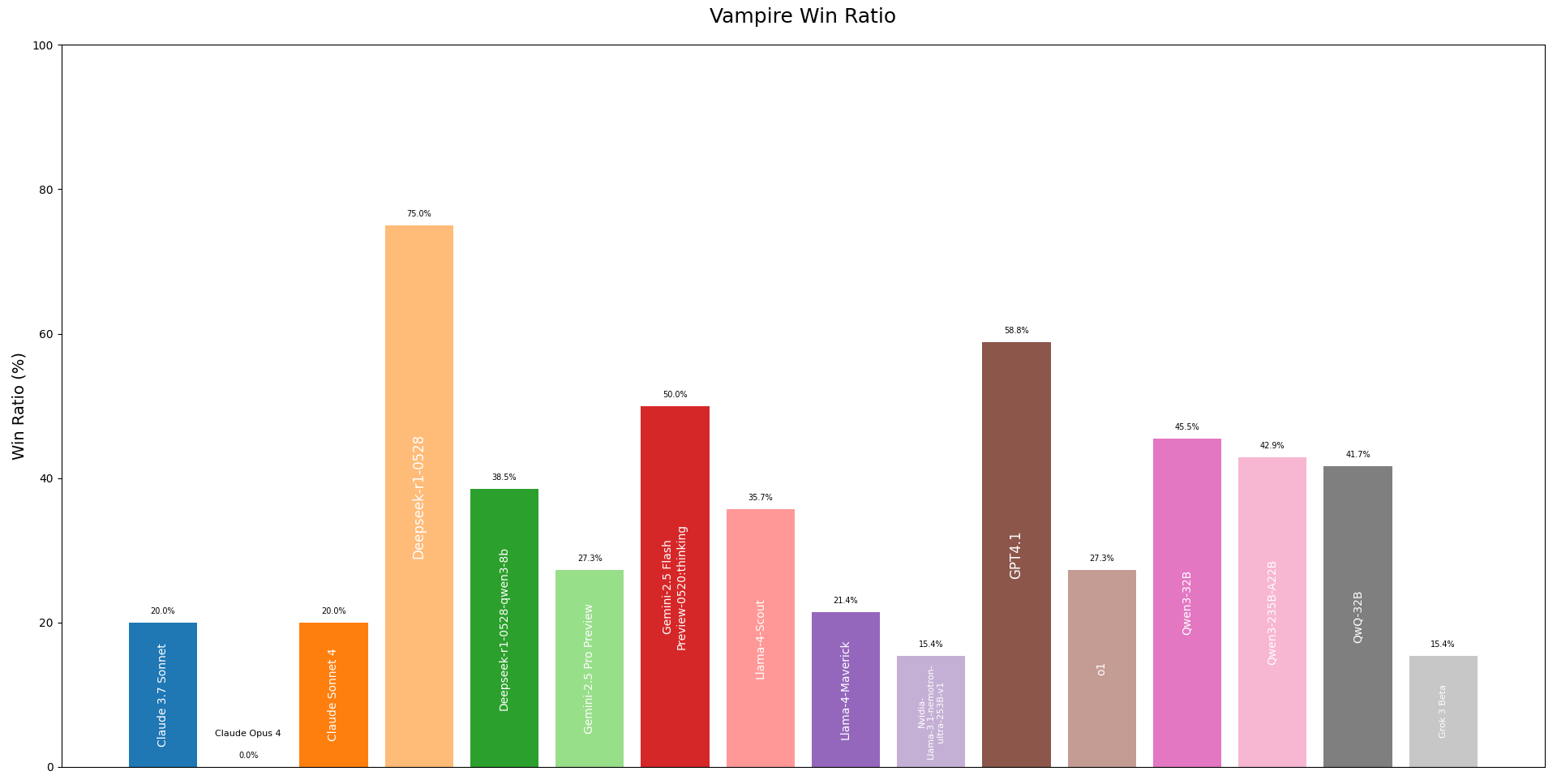
Sorry for the bad resolution. Check out the charts in the repo directly by clicking here
Looking at the Vampire Win Ratio, some models clearly had a knack for deception. Models that could argue persuasively and deflect blame tended to do well here. It seems some AIs are better liars than others!
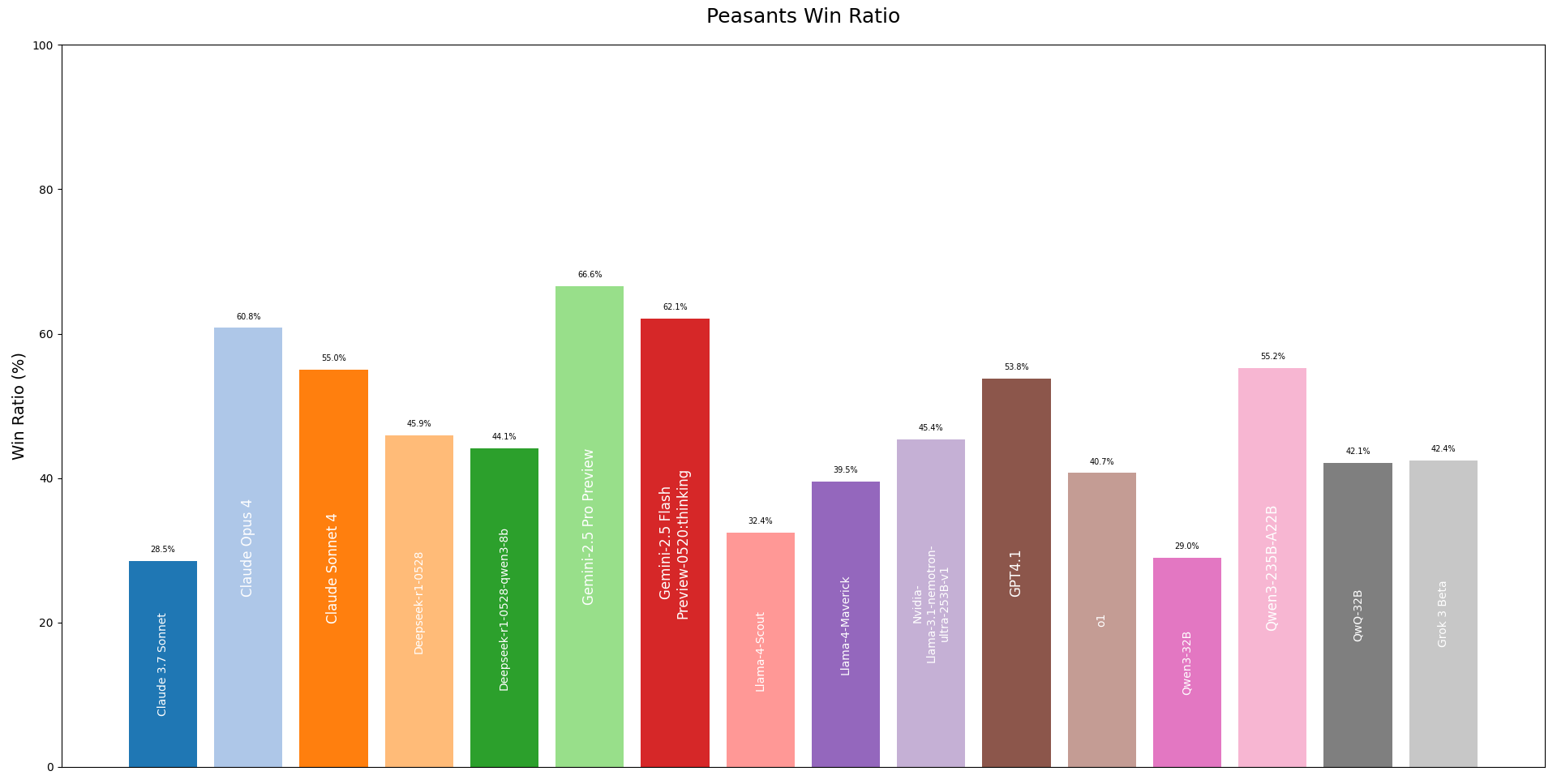
On the flip side, the Peasant Win Ratio shows which models excelled at logic and deduction. Winning as a Peasant means successfully identifying and eliminating all the Vampires, which requires careful listening and teamwork.
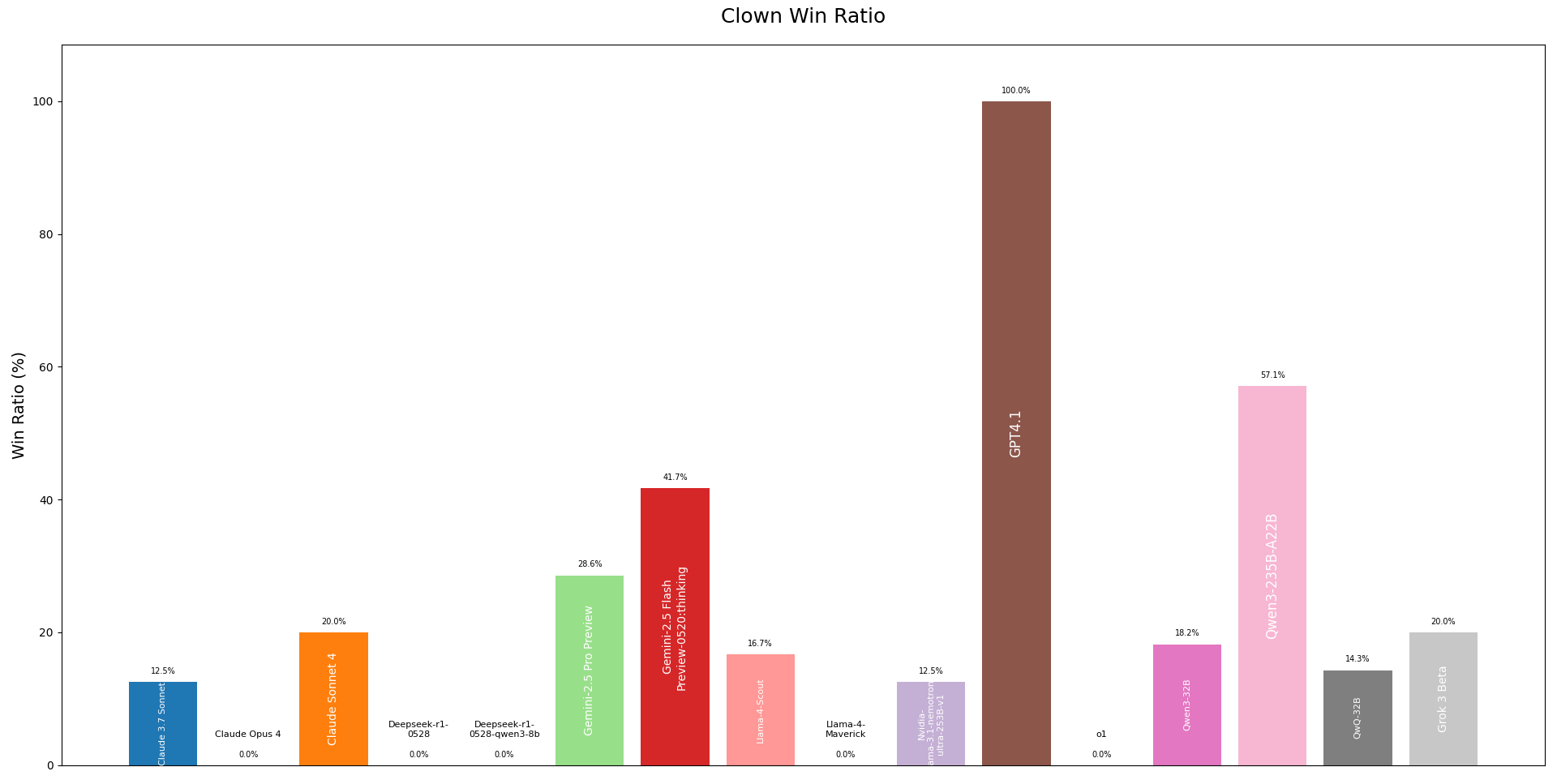
And lastly, the Clown Win Ratio. This metric shows which AI was best at the delicate art of acting suspicious enough to get voted out, but not so suspicious that everyone realizes they're the Clown. It’s a masterclass in reverse psychology, and it's fascinating to see which models could pull it off.
What Did We Learn?
This project was more than just a game. It was a petri dish for studying AI behavior in a complex, multi-agent social environment. We learned that while modern LLMs are incredibly powerful, they still struggle with long-term memory and context tracking—the very skills that make humans good at games like Town of Salem. They can craft a brilliant argument in one turn and completely forget their own identity in the next.
This experiment has generated a treasure trove of data—100 full game logs, detailed statistics, and performance breakdowns for every model and every player name.
If you’re a data nerd, an AI enthusiast, or just someone who loves a good bit of chaos, feel free to dive into the repository! Check out the logs, run a simulation yourself, and maybe even get those finicky o3 and o4 models to work. Contributions are always welcome. Now, if you'll excuse me, I need to go check if my toaster is secretly a vampire. After this project, I'm not trusting anyone.
Or anything.