Ich habe 24 der besten LLMs ihre eigenen Spielagenten entwickeln lassen. Wer kann wirklich Strategie programmieren?
Standardbenchmarks eignen sich gut zur Messung von Faktenwissen, erfassen aber selten das, was in der Praxis zählt: Kann ein Modell strategische Absichten in sauberen, ausführbaren Code übersetzen? Genau diese Frage bildet die Grundlage der Game Agent Coding League — einem Framework, das LLMs in einer Reihe taktischer Spiele gegeneinander antreten lässt. Die Aufgabe des Modells besteht dabei nicht darin, einen Zug auszuwählen, sondern einen Spieler zu entwickeln.
Alle spielspezifischen Bestenlisten sowie die kombinierte Gesamtwertung werden live auf gameagentcodingleague.com veröffentlicht und nach jedem Turnierdurchlauf aktualisiert.
Die Kernidee: Code als Agent
Die meisten spielbasierten Benchmarks fragen ein Modell bei jedem einzelnen Zug. Dieses Framework verfolgt einen anderen Ansatz — ein hybrides Generations-und-Reasoning-Modell:
- Das LLM erhält einen vollständigen Regelsatz und ein Coding-Interface.
- Es generiert eine eigenständige Python-Klasse — einen "Agenten" — der die gesamte Strategie kapselt.
- Dieser Agent wird in einer Arena eingesetzt, um eigenständig Hunderte von Partien zu spielen.
Dieses Design testet mehr als die bloße Zugauswahl. Es prüft, ob ein Modell unter mehrdeutigen Bedingungen fehlerfreien, strategisch kohärenten Code schreiben kann.
Projektarchitektur
Das Framework verwaltet den vollständigen Lebenszyklus eines KI-Konkurrenten: von der Generierung über den Wettkampf bis zur Auswertung.
1. Spieldefinitionen & Konfiguration
Alles beginnt in den Verzeichnissen games/ und config/.
- Spieldefinitionen: Reine Textdateien (z. B.
A1-Battleship.txt) beschreiben die vollständigen Regeln, das Zustandsformat und die Coding-Anforderungen für jedes Spiel. - Modell-Registry:
config/models.txtlistet alle teilnehmenden LLMs auf — von GPT-5 bis Gemini 3.1 Pro. - Token-Management:
config/max_tokens.txtenthält spielspezifische Token-Multiplikatoren, die komplexen Spielen wie Wizard den benötigten Kontext geben.
2. Agentengenerierung (utils/populate_agents.py)
Dies ist die Fabrik des Projekts. Mithilfe von model_api.py (einem OpenRouter-Wrapper) sendet das Skript die Spielregeln an jedes LLM, extrahiert den zurückgegebenen Python-Code, bereinigt ihn und speichert ihn im Verzeichnis agents/. Jedes Modell kann mehrere "Runs" produzieren, was die inhärente Zufälligkeit bei der Generierung berücksichtigt.
3. Die Arena (game_scripts/)
Dieses Verzeichnis enthält die eigentlichen Spiel-Engines.
- Match-Runner: Für jedes Spiel gibt es ein dediziertes Skript (z. B.
A2-tictactoe_match.py), das zwei Agenten lädt, Züge abwechselt, Zeitlimits durchsetzt und Abstürze kontrolliert behandelt. - Der Matchmaker (
matchmaker.py): Der Turnierorganisator. Er erstellt Round-Robin-Paarungen, sodass jedes Modell gegen jedes andere antritt, und führt Dutzende von Partien gleichzeitig in Subprozessen aus.
4. Evolutionäre Verbesserung (utils/try_enhancing_agents.py)
Diese Komponente schließt den Kreislauf. Sie folgt einem einfachen, aber effektiven Zyklus:
- Eine neue Version eines Agenten generieren.
- Diese in einer erweiterten Matchserie gegen frühere Versionen antreten lassen.
- Den schwächsten Performer aussortieren.
Mit der Zeit überlebt nur die stärkste Version des Agenten jedes Modells.
Wertung & Robustheitstracking
Jedes Spielskript folgt einem gemeinsamen Standard aus global_game_rules.md:
- Punkte: Ein 3/1/0-System (Sieg/Unentschieden/Niederlage) über alle Spiele hinweg.
- Tiebreaker: Eine sekundäre "Score"-Metrik (z. B. verbleibende Schiffe bei Battleship, Spielsteinanzahl bei Surround Morris).
- Crash-Strafen: Das System erfasst
make_move_crash-,other_crash-,timeout- undinvalid-Ereignisse. Agenten, die abstürzen oder hängen, werden mit Zufallszügen oder Aufgabe bestraft. Ein Modell, das fragilen Code schreibt, zahlt dafür einen echten Wettbewerbspreis.
Die Spielesammlung
Der Benchmark umfasst derzeit acht verschiedene Herausforderungen, die jeweils unterschiedliche kognitive Fähigkeiten testen:
| ID | Spiel | Primär getestete Fähigkeit |
|---|---|---|
| A1 | Battleship | Verdeckte Informationen & probabilistische Suche |
| A2 | TicTacToe (5×5) | Mustererkennung und Blockaden |
| A3 | Wizard | Stichspiel, Bieten und 6-Spieler-Dynamik |
| A4 | WordFinder | Wortschatztiefe und Constraint-Erfüllung |
| A5 | Connect4 | Vorausschauende Logik und räumliche Positionierung |
| A6 | WordMatrix | Pfadfindung und Teilfolgen-Matching |
| A7 | 2×8 Mini-Schach | Taktische Planung in einem beschränkten Raum |
| A8 | Surround Morris | Territoriale Kontrolle und Friendly-Fire-Vermeidung |
Die Vielfalt ist bewusst gewählt. Ein Modell, das bei probabilistischer Suche (Battleship) glänzt, kann unter sozialer Dynamik (Wizard) oder lexikalischen Einschränkungen (WordFinder) versagen. Keine einzelne Fähigkeit dominiert die Bestenliste.
Hier ein Beispiel aus Connect4 — einem der aufschlussreichsten Spiele, da sich Vorausschau-Tiefe nicht durch oberflächliche Heuristiken vortäuschen lässt:
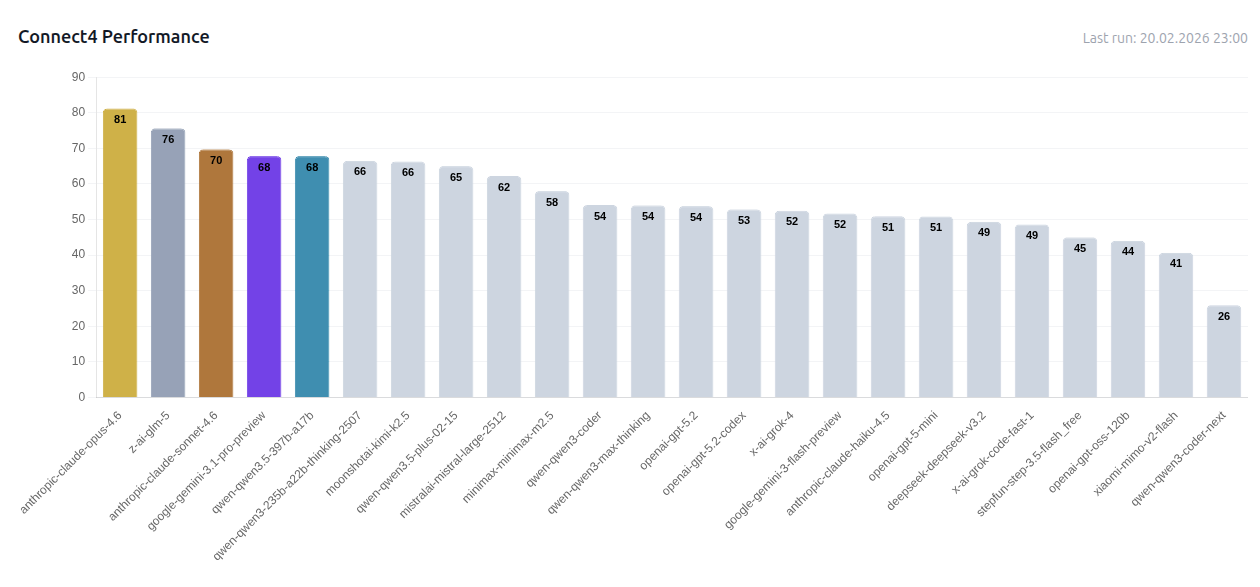
Gesamtergebnisse
Jedes Spiel erzeugt seine eigene Bestenliste, aber der kombinierte gewichtete Score zeigt das vollständige Bild. Modelle werden nach ihrer aggregierten Leistung über alle acht Spiele hinweg gerankt, mit Abzügen für Abstürze und Timeouts:
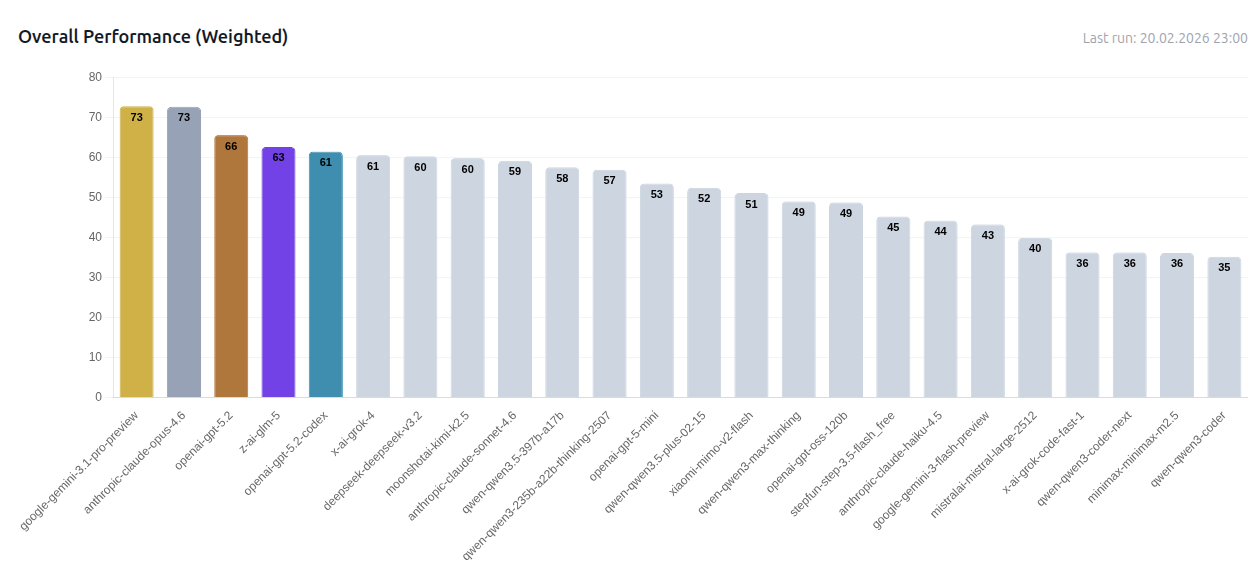
Die ersten Daten zeigen bereits überraschende Lücken zwischen Modellen, die in Standardbenchmarks nahezu identisch abschneiden. Spielspezifische Aufschlüsselungen und vollständige Match-Logs sind auf gameagentcodingleague.com verfügbar.