I Made 24 Best LLMs Engineer Their Own Game Agents. Here's Who Can Actually Code Strategy.
Standard benchmarks are fine for measuring raw knowledge, but they rarely capture what matters in practice: can a model translate strategic intent into clean, executable code? That question is the foundation of the Game Agent Coding League — a framework that pits LLMs against each other through a suite of tactical games, where the model's job isn't to pick a move, but to engineer a player.
All game-by-game leaderboards and combined weighted results are published live at gameagentcodingleague.com, updated after every tournament run.
The Core Idea: Code-as-Agent
Most game-playing benchmarks prompt a model for every single move. This framework takes a different approach — a hybrid generation-and-reasoning model:
- The LLM receives a full set of game rules and a coding interface.
- It generates a standalone Python class — an "Agent" — that encapsulates its entire strategy.
- That agent is deployed into an arena to play hundreds of matches autonomously.
This design tests something deeper than move selection. It tests whether a model can write bug-free, strategically coherent code under ambiguous constraints.
Project Architecture
The framework manages the full lifecycle of an AI competitor: from generation, through competition, to scoring.
1. Game Definitions & Config
Everything begins in the games/ and config/ directories.
- Game Definitions: Plain text files (e.g.,
A1-Battleship.txt) describe the full rules, state format, and coding requirements for each game. - Model Registry:
config/models.txtlists every participating LLM — from GPT-5 to Gemini 3.1 Pro. - Token Management:
config/max_tokens.txtprovides per-game token multipliers, giving complex games like Wizard the context they need.
2. Agent Generation (utils/populate_agents.py)
This is the factory. Using model_api.py (an OpenRouter wrapper), the script sends game rules to each LLM, extracts the returned Python code, sanitizes it, and saves it into the agents/ folder. Each model can produce multiple "runs," which accounts for the inherent randomness in generation.
3. The Arena (game_scripts/)
This directory contains the actual game engines.
- Match Runners: Each game has a dedicated script (e.g.,
A2-tictactoe_match.py) that loads two agents, alternates turns, enforces time limits, and handles crashes gracefully. - The Matchmaker (
matchmaker.py): The tournament orchestrator. It builds round-robin fixtures so every model faces every other model, and runs dozens of matches concurrently via subprocesses.
4. Evolutionary Improvement (utils/try_enhancing_agents.py)
This component closes the loop. It follows a simple but effective cycle:
- Generate a new version of an agent.
- Run it through an extended series of matches against its own previous versions.
- Discard the weakest performer.
Over time, only the fittest version of each model's agent survives.
Scoring & Robustness Tracking
Every game script follows a shared standard defined in global_game_rules.md:
- Points: A 3/1/0 (Win/Draw/Loss) system across all games.
- Tie-breakers: A secondary "Score" metric (e.g., ships remaining in Battleship, piece count in Surround Morris).
- Crash Penalties: The system tracks
make_move_crash,other_crash,timeout, andinvalidevents. Agents that crash or stall are penalized with random moves or forfeits. A model that writes brittle code pays a real competitive price.
The Game Suite
The benchmark currently covers eight distinct challenges, each targeting a different cognitive skill:
| ID | Game | Primary Skill Tested |
|---|---|---|
| A1 | Battleship | Hidden information & probabilistic search |
| A2 | TicTacToe (5×5) | Pattern recognition and blocking |
| A3 | Wizard | Trick-taking, bidding, and 6-player social dynamics |
| A4 | WordFinder | Vocabulary depth and constraint satisfaction |
| A5 | Connect4 | Look-ahead logic and spatial positioning |
| A6 | WordMatrix | Pathfinding and subsequence matching |
| A7 | 2×8 Mini Chess | Tactical planning in a constrained space |
| A8 | Surround Morris | Territorial control and friendly-fire avoidance |
The diversity is deliberate. A model that excels at probabilistic search (Battleship) may fall apart under social dynamics (Wizard) or struggle with lexical constraints (WordFinder). No single skill dominates the leaderboard.
Here's an example from Connect4 — one of the more revealing games because look-ahead depth is hard to fake with shallow heuristics:
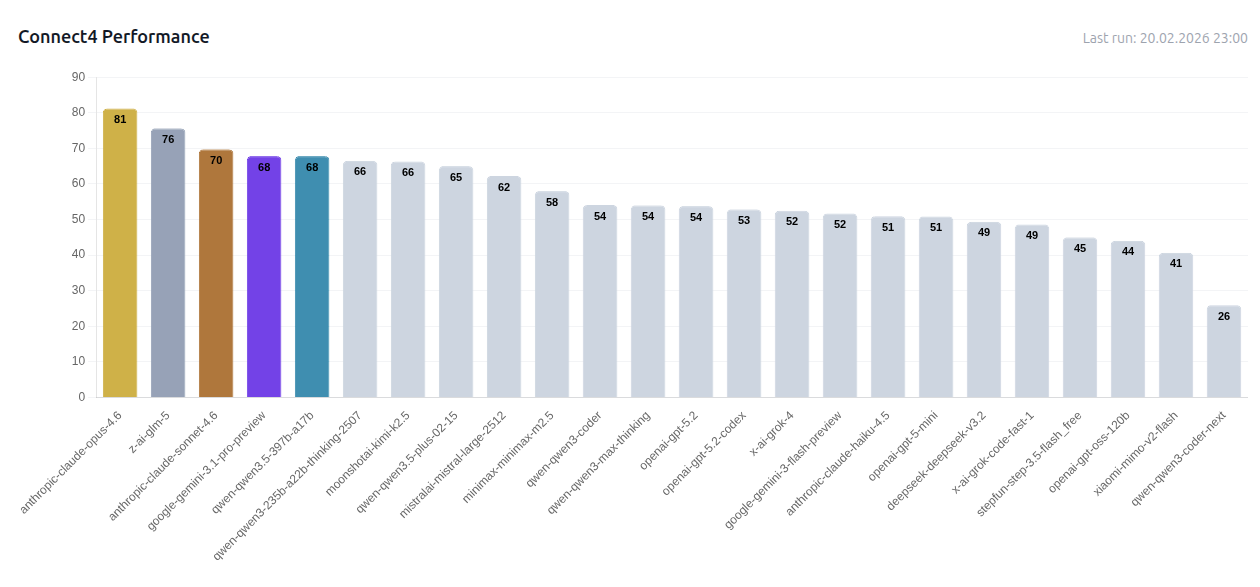
Overall Results
Each game produces its own leaderboard, but the combined weighted score is where the full picture emerges. Models are ranked by aggregated performance across all eight games, penalized for crashes and timeouts:
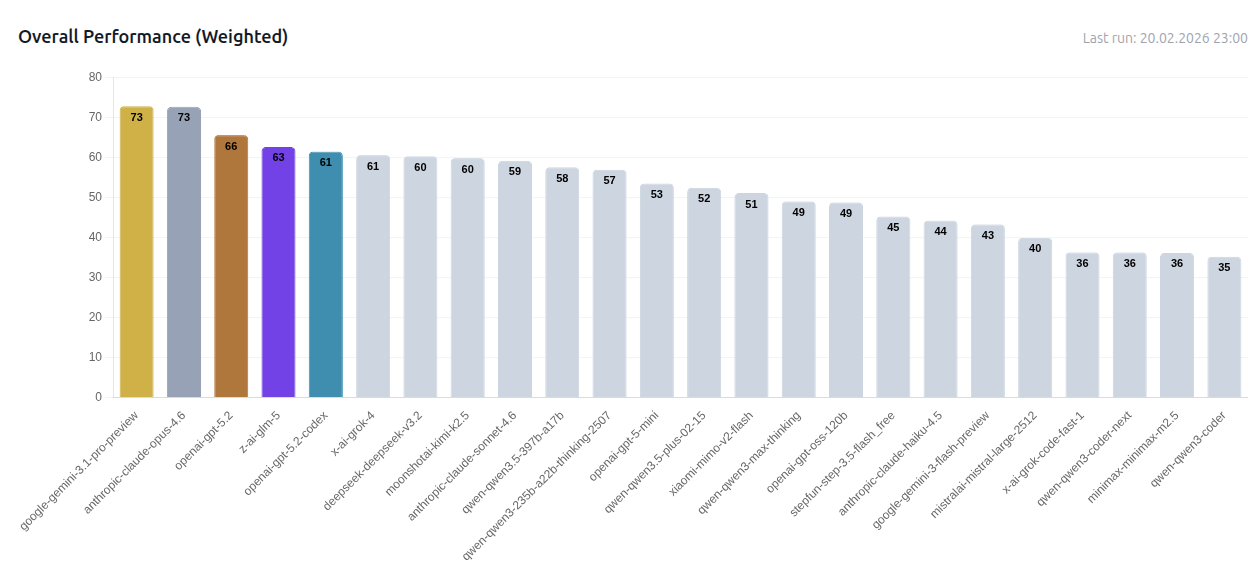
The early data is already surfacing some surprising gaps between models that look nearly identical on standard benchmarks. Per-game breakdowns and full match logs are available at gameagentcodingleague.com.