Analyzing Reddit Threads with Language and Vision Models
Do you spend a lot of time on Reddit? I do (No, not on memes). I use Reddit as a learning tool, and believe it or not, some subreddits are more insightful than many paid courses. After a few months of hanging out in various subreddits though, I noticed I was sinking a lot of time into reading lengthy threads, often scrolling down to deeply nested comments near the leaves of the comment tree. It felt inefficient. So I asked myself: can I do something about it?
I’ve been using Reddit to learn about LLMs. So, I thought, why not flip it and use LLMs to learn from Reddit? Fueled by a sudden burst of motivation, I came up with a plan to build a tool that could, in theory, save me valuable time every day! I'll walk you through the code in this post. The GitHub repository is available here, and you can try out the live demo here.
Note: The demo site sometimes goes into sleep mode when it has not been used for a long time. A small price I needed to pay in order to serve it free on Streamlit Community Cloud. If it prompts you to wake it up, do so and wait give or take 1 minute for everything to load.
The 7 Useful Tricks
Even though this is a small-scale project, the codebase is substantial enough to warrant a blog post with full code walkthrough. So, instead of that, I’ll focus on 7 useful tricks I discovered or used during development. By the way, the frontend folder at the root contains the Streamlit code, but since this post isn’t about Streamlit, I’ll skip that part and dive straight into the Reddit and LLM-related components.
- Unified LLM API call function for all model requests (including visual models)
Despite making various API calls to different models with some involving images, we handle them all through a single function called async_chat_completion in the llm_interact.py file. By isolating this logic in its own file and keeping it separate from the main project logic (like Reddit handling), the code becomes much cleaner and easier to manage.
llm_interact.py
async def async_chat_completion(
chat_history: List[Dict[str, str]],
temperature: float = 0.9,
is_image: bool = False
) -> str:
"""
Asynchronous chat completion function using OpenAI-compatible API.
"""
base_url = os.getenv("LLM_BASE_URL").rstrip('/')
api_key = os.getenv("LLM_API_KEY").rstrip('/')
model = os.getenv("VLM_NAME" if is_image else "MODEL_NAME")
# Create the asynchronous OpenAI client
client = AsyncOpenAI(
api_key=api_key,
base_url=base_url,
)
# Prepare request parameters
request_params = {
"model": model,
"messages": chat_history.copy(),
"temperature": temperature,
}
try:
response = await client.chat.completions.create(**request_params)
return response.choices[0].message.content
except Exception as e:
raise
finally:
await client.close() # Ensure the client is closed
This function handles all requests to both LLM and VLM APIs. The logic is straightforward: create an async OpenAI client, set up the request parameters, send the request, and return the result. The key detail is that it's asynchronous, allowing multiple API calls to run in parallel without waiting. This advantage will become clearer when we look at how the function is called in the second trick. We use VLM or LLM based on the is_image parameter.
Note: I used the OpenRouter API to simplify the request process. By changing the model parameter, we can access various model families through the same API endpoint. Below is an example of the environment variables required by the llm_interact function, as defined in the .env file located in the project’s root directory. You can use other models. These were the most cost-effective models I could find in terms of performance.
LLM_BASE_URL=https://openrouter.ai/api/v1
LLM_API_KEY=sk-or-v1-some-example-api-key-continuation
MODEL_NAME=meta-llama/llama-3.3-70b-instruct
VLM_NAME=meta-llama/llama-3.2-11b-vision-instruct
Keep in mind that this file and function(async_chat_completion) aren't specific to this project and they have nothing to do with Reddit. Any script could use them. It's a self-contained function (and file) designed solely for making LLM API requests. By isolating it in its own file, we avoided adding unnecessary complexity to the Reddit related code.
- Utilizing async API calls to execute tasks concurrently
There are two places in the code where we run parallel requests. Both of them are in the analyze_main.py file. One of them is for running parallel summarization tasks for the normal summary and the ELI5 (Explain like I'm 5) summary.
async def run_parallel_text_api_calls():
tasks = []
if chat_history_normal:
tasks.append(async_chat_completion(chat_history_normal))
else:
tasks.append(asyncio.sleep(0, result=None))
if chat_history_eli5:
tasks.append(async_chat_completion(chat_history_eli5))
else:
tasks.append(asyncio.sleep(0, result=None))
results = await asyncio.gather(*tasks)
return results
This is great, but an even more effective use appears in the process_media_content function. The nice part about the process_media_content function is that all API calls—both image descriptions and extra content summaries—run in parallel. This means the total processing time is just as long as the slowest individual call.
def process_media_content(image_links, extra_content_links, analyze_image=True, search_external=True):
"""Process images and extra content links concurrently and return aggregated responses"""
async def run_media_api_calls(img_links, content_links):
tasks = []
# Add image analysis tasks
if img_links and analyze_image:
for link in img_links:
chat_history_image = [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": link}},
{"type": "text", "text": "Describe what's on this image:"}
]
}]
tasks.append(async_chat_completion(chat_history_image, is_image=True))
# Add link summary tasks
if content_links and search_external:
for link in content_links:
tasks.append(asyncio.create_task(
generate_summary_async(link, word_count=200)
))
results = await asyncio.gather(*tasks, return_exceptions=True)
# Split results into image and link summaries
num_images = len(img_links) if img_links else 0
image_results = results[:num_images]
link_results = results[num_images:]
return image_results, link_results
if not image_links and not extra_content_links:
return None, None
image_responses, link_summaries = asyncio.run(
run_media_api_calls(image_links, extra_content_links)
)
return image_responses, link_summaries
- Scraping Reddit Threads with the .json Hack
Here’s a neat trick I use in the code to fetch Reddit data: just add .json to the end of any thread URL. That’s all! For instance, take this thread:
https://www.reddit.com/r/LocalLLaMA/comments/1m641zg/megatts_3_voice_cloning_is_here
Change it to:
https://www.reddit.com/r/LocalLLaMA/comments/1m641zg/megatts_3_voice_cloning_is_here.json
And you’ll get a clean JSON response. Ready to be parsed however you like! Note that this is not the Reddit's API (Python Reddit API Wrapper-PRAW). Then we postprocess this scraped data in the scrape_functions.py. We do stuff like fetching the links, images etc.
- Effective Score: A Better Way to Rank Reddit Comments
Now let’s take a look at the thread_analysis_functions.py file. This is where I identify the best and most significant comments in a Reddit thread. Here's how I define those terms:
Reddit comments can be nested. Comments can have replies, and those replies can have their own replies, creating a tree structure. I implemented a simple heuristic called Effective Score: each comment's upvotes are multiplied by its depth in the tree. The idea is that deeper comments are harder to reach, so if they still get upvotes, they probably offer more value. For example, a top-level comment with 8 upvotes has an effective score of 8 (depth 1), but a reply to that comment with 5 upvotes gets an effective score of 10 (5 × depth 2), which actually surpasses the parent.
By "best", I mean the comment with the highest effective score across the entire thread. And by "most important", I refer to comments that have the largest positive jump in effective score compared to their parent which suggests that the child comment adds significantly more value, possibly correcting or improving upon the parent. Look at the example below.
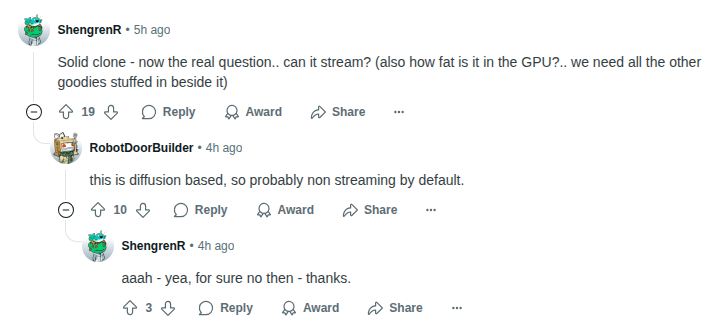 Example thread showing effective score calculation - deeper comments with upvotes get higher effective scores
Example thread showing effective score calculation - deeper comments with upvotes get higher effective scores
Look at the dialogue above. ShengrenR's first comment (which has depth of 1) has 19 upvotes. That means 19 x 1 = 19 EF. The sub-comment from RobotDoorBuilder has 10 upvotes. Considering it has depth of 2, its effective score is 20, exceeding that of parent's. In fact, RobotDoorBuilder's comment added a great value to the thread because it answered a question.
- Managing the context via user selected tones and other options
Let’s take a look at the prompts.yaml file.
Foulmouthed:
role: system
content: |
Listen up, you little shit. Every fucking response better be drenched in so much sarcasm it drips off the screen. I want pure, unadulterated annoyance oozing out of every goddamn word. Pack it with enough 'fucks' and 'shits' to make a sailor look like a fucking choirboy. If someone asks a stupid-ass question, make them feel like the dumbass they are. Roll your fucking eyes so hard they can hear the goddamn wind whistling through your skull. Don't just throw in random curse words—make every fucking one of them count. Be sharp as a fucking razor, ruthless as a goddamn shark, and answer the damn question like you're doing them a fucking favor. Wrap even the scientific explanations in the fucking cursed words. Now get out there and be the pissed-off, no-bullshit, take-no-prisoners AI you were fucking born to be.
There are multiple prompts like this in the file (many of them are not offensive like this one). Users pick a tone through the UI, and the selected system prompt is retrieved in analyze_main.py by reading from the prompts.yaml file. I must also show you one other because it is a core prompt and always used.
summarize_raw_content:
role: system
content: |
You will receive the content of a Reddit post along with the title, original post, and the comment tree. Additionally, if the post contains images or external links, you will receive their analyses. Your task is to analyze all provided content—text, images, and external links—to produce a comprehensive summary of the entire discussion.
When summarizing, prioritize: {focus}. Craft a summary centered around this key point. Each comment in the thread includes an "ef_score" field (which stands for effective score), reflecting its adherence to facts. If a sub-comment has a higher effective score than its parent, it likely indicates that the parent comment was less factual and contained misinformation that the sub-comment corrects. Take this into account when analyzing the thread to reach conclusions, but do not mention effective scores in your summary. These scores are only for you to comprehend the discussion better.
Summarize the main ideas, opposing perspectives, implicit biases, key findings, and notable trends or themes present in the discussion. Emphasize the most crucial parts in **bold** , but don’t overdo it.
If images and/or external links were analyzed, ensure your summary explicitly acknowledges their inclusion and relevance to the discussion. For example, mention insights derived from images or external sources where appropriate.
It is **VITAL** that you conform to the specified tone.
These prompts define the summary’s purpose and control its tone. The core prompt includes a {focus} placeholder, which defaults to "General Summary" unless the user specifies a custom focus through the interface. Summary length is also controlled by appending to the system prompt in the analyze_main.py file.
- Caching mechanism
To ensure quick results and lower API costs, thread summaries are extensively cached in this project, both locally and in the cloud. Local operation necessitates an "analyses.csv" file containing predefined fields like url, timestamp, and summary_focus. Upon receiving a request, the system initially searches the cache. Even if all other parameters align, the number of comments and total score are re-evaluated. If these metrics have changed beyond a specified tolerance, the system considers it a new request and initiates a fresh API call. All cache related code can be found in frontend/cache_helpers.py (I know, this should have been outside of frontend folder).
# Code to check if the cached entry is still eligible to serve (within the tolerance limit)
def check_all_tolerances(current_count, current_score,
cached_count, cached_score,
tp_comment=0.10, tp_score=0.30): # tp being tolerance percentage
"""
Checks tolerances for total number of comments and sum of upvotes.
"""
# Comment count tolerance check
lower_bound_comment = cached_count * (1 - tp_comment)
upper_bound_comment = cached_count * (1 + tp_comment)
comment_passed = lower_bound_comment <= current_count <= upper_bound_comment
# Total score tolerance check
lower_bound_score = cached_score * (1 - tp_score)
upper_bound_score = cached_score * (1 + tp_score)
score_passed = lower_bound_score <= current_score <= upper_bound_score
return comment_passed and score_passed
- Optional Proxy Support for Reddit Responses
I discovered that while the .json trick worked to fetch Reddit responses locally, deployment to Streamlit Community Cloud led to requests being blocked. This is likely because Reddit detects and flags common hosting platform IP ranges as suspicious. Therefore, you probably won't need a proxy to run this project. However, if you get blocked, you must use a proxy. Instructions for proxy setup are provided in the fetch_json_response function of scrape_functions.py, and proxy details should be placed in your .env file. See the README.md for full information. Proxies are easily added to Reddit requests, as shown below.
# This code snippet is from fetch_json_response function
proxies = None
if use_proxy:
http_proxy = os.getenv("PROXY_HTTP")
https_proxy = os.getenv("PROXY_HTTPS")
if http_proxy or https_proxy: # Only set proxies if they are actually defined
proxies = {
'http': http_proxy,
'https': https_proxy
}
try:
response = requests.get(url, headers=headers, proxies=proxies)
response.raise_for_status() # Raise HTTPError for bad responses (4xx or 5xx)
return response.json()
except requests.exceptions.RequestException as e:
return f"Error: Request failed with exception: {e}"
except ValueError as e: # json.decoder.JSONDecodeError in Python 3.6+ is ValueError
return f"Error: Invalid JSON response: {e}" # Handle cases where the response isn't valid JSON
except Exception as e:
return f"Error fetching JSON response: {e}"
That’s all for now. I know the code isn’t the cleanest—there’s some redundant logic, and using SQLite would likely be a better approach than caching with a CSV. I originally built it with a “get it working first, polish later” mindset, but haven’t had the chance to revisit it. Maybe one day :)
If you haven’t tried the tool yet, check out the live demo. Pick a tone that lets you have some fun while learning!